Several Problems about Linux Kernel version 0.11
There are several problems, which deserve being thought carefully, about linux kernel(version 0.11).
I will not give detail answers to the following questions, but give a brief outline for each question.
I do NOT promise the answers is exactly correct.
if you find any mistake, please email liuxuebao AT ict.ac.cn. Thank you!
Have fun!
Good luck!
1. Why BIOS is executed in the beginning after computer setup? Why not the Operating System?
The root cause might be the von Neumann architecture.(CPU can only execute the code residing in the main memory.)
The main memory is usually made of RAM in current computers.(RAM will lose all datas without power.)
Therefore, there is no code in main memory to be executed just after computer setup.
The code contained in BIOS will be executed first to boot the OS in the external storage such as disk, floppy and so on.
2. Why BIOS just loads the first sector of the disk, which is so-called bootsect, and the successive sectors is loaded by bootsect? Why not load all sectors through the BIOS?
It might be historical reasons that Only the first sector of the disk is loaded by BIOS.Why not the second one, the third one and so on? It is just a convention.
But the connvention is necessary and crucial because the BIOS and the OS are developed seperately by different teams. They known nothing about each other and cannot cooperate with each other without the conventions. A good convention can give both of the BIOS and the OS scalability. The BIOS or the OS just cares about the functionality of itself and conform to the conventions.
Different OSs might have different memory layouts. So, the BIOS load the bootsect rather than all of the sectors in order that the OS manage the memory itself and the BIOS keep simple and naive. The better the convention is, the less the BIOS and OS depend on each other.
3. Why the BIOS load the bootsect to the address 0x07c00 instand of 0x00000? Why bootsect is moved to the address 0x90000 after being loaded? Why not load to the correct address at the first time?
It might also be historical reasons.
In the convention, the interrupt vector table is loaded to the address 0x00000. Obviously, if you load the bootsect here, the interrupt vector table will be overwrittern by it. Nothing serious will happen if you are sure what you do.
The bootsect is moved to the address 0x90000 becuase of the memory layouts of linux kernel(version 0.11). You can give some details about the layouts.
4. How the bootsect, the setup and the head cooperate(connect) with each other? Give some evidences(code).
We can easily find the follow assembly code in boot/bootsect.s, which makes the execution turn to setup.
SETUPSEG = 0x9020 ! setup starts here
...
! after that (everyting loaded), we jump to
! the setup-routine loaded directly after
! the bootblock:
jmpi 0,SETUPSEG
Similarly, the follow assembly code, which makes the execution turn to head, can be found in boot/setup.s.
! Well, now is the time to actually move into protected mode. To make
! things as simple as possible, we do no register set-up or anything,
! we let the gnu-compiled 32-bit programs do that. We just jump to
! absolute address 0x00000, in 32-bit protected mode.
mov ax,#0x0001 ! protected mode (PE) bit
lmsw ax ! This is it!
jmpi 0,8 ! jmp offset 0 of segment 8 (cs)
5. What is the meaning of 8 of the code jmpi 0, 8 in the boot/setup.s?
In 32-bit protected mode, the CS (Code Segment register) is used as code segment selector. The 8 (1000b) is the value of CS.
A segment selector is a 16-bit identifier for a segment. It does not point directly to the segment, but instead points to the segment descriptor that defines the segment. A segment selector contains the following items:
Index (Bits 3 throuth 15) -- Selects one of 8192 descriptors in the GDT or LDT.
TI(table indicator) flag (Bit 2) -- Specifies the descriptor table to use:clearing this flag selects the GDT; setting this flag selects the current LDT.
Requested Privilege Level(RPL) (Bits 0 and 1) -- Specifies the privilege level of the selector. The privilege level can range from 0 to 3, with 0 being the most privileged level.
Therefore, the 8 (1000b) means:
- Index is 1.
- Selecting GDT.
- RPL is 0
The code jmpi 0, 8 just indicates that we just jump to absolute address 0x00000000, in 32-bit protected mode.
6. What is protected in the protected mode? Where does the protection work? What is the meaning and purpose of privilege level? Is the Paging able to provide protections?
In protected mode, the IA-32 architectures provides a protections mechanism that operates at both the segment level and the page level.
This protection mechanism provides the ability to limit access to certain segments or pges based on privilege levels.
When the protection mechanism is used, each memory reference is checked to verify that it satisfies various protection checks. The protection checks that are performed fall into the following categories:
- Limit checks.
- Type checks.
- Privilege level checks.
- Restriction of addressable domain.
- Restriction of procedure entry-points.
- Restriction of instruction set.
All protection violtion results in an exception being generated.
There are four privilege levels for segments and two privilege levels of pages in protected mode. The protection mechanism wiil prevent the less privileged code from accessing the more privileged code and data in any but a contorlled, defined manner.
7. GDT is set in setup. However, why is it discarded and set again in head? Why is it set twice instead of once?
The GDT which is set in setup will be overwritten according to the memory layout of linux kernel (version 0.11). So you must set it again in head
8. Where is the task_struct of Process 0? What is the content of it?
I do NOT known where the task_struct of Process 0 is. But when I trace the linux kernel in my machine with bochs, I found it at the address 0x17280. Of course, it is meaningless.
The content of it is as follow:
/*
* INIT_TASK is used to set up the first task table, touch at
* your own risk!. Base=0, limit=0x9ffff (=640kB)
*/
#define INIT_TASK \
/* state etc */ { 0,15,15, \
/* signals */ 0,{ { },},0, \
/* ec,brk... */ 0,0,0,0,0,0, \
/* pid etc.. */ 0,-1,0,0,0, \
/* uid etc */ 0,0,0,0,0,0, \
/* alarm */ 0,0,0,0,0,0, \
/* math */ 0, \
/* fs info */ -1,0022,NULL,NULL,NULL,0, \
/* filp */ {NULL,}, \
{ \
{0,0}, \
/* ldt */ {0x9f,0xc0fa00}, \
{0x9f,0xc0f200}, \
}, \
/*tss*/ {0,PAGE_SIZE+(long)&init_task,0x10,0,0,0,0,(long)&pg_dir,\
0,0,0,0,0,0,0,0, \
0,0,0x17,0x17,0x17,0x17,0x17,0x17, \
_LDT(0),0x80000000, \
{} \
}, \
}
It might look like this in memory.
9. Draw a picture describing the relationship between the first 7 pages after paging. Give some evidences(code).
The following picture comes from the book -- The Art of Linux Kernel Design.
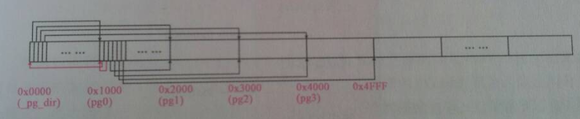
Paging code is as follow:
setup_paging:
movl $1024*5,%ecx /* 5 pages - pg_dir+4 page tables */
xorl %eax,%eax
xorl %edi,%edi /* pg_dir is at 0x000 */
cld;rep;stosl
movl $pg0+7,_pg_dir /* set present bit/user r/w */
movl $pg1+7,_pg_dir+4 /* --------- " " --------- */
movl $pg2+7,_pg_dir+8 /* --------- " " --------- */
movl $pg3+7,_pg_dir+12 /* --------- " " --------- */
movl $pg3+4092,%edi
movl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */
std
1: stosl /* fill pages backwards - more efficient :-) */
subl $0x1000,%eax
jge 1b
xorl %eax,%eax /* pg_dir is at 0x0000 */
movl %eax,%cr3 /* cr3 - page directory start */
movl %cr0,%eax
orl $0x80000000,%eax
movl %eax,%cr0 /* set paging (PG) bit */
ret /* this also flushes prefetch-queue */
10. What is the content of 184 bytes just before IDT after head finish executing? Why the code is left?
The content is as follow:
after_page_tables:
pushl $0 # These are the parameters to main :-)
pushl $0
pushl $0
pushl $L6 # return address for main, if it decides to.
pushl $_main
jmp setup_paging
L6:
jmp L6 # main should never return here, but
# just in case, we know what happens.
/* This is the default interrupt "handler" :-) */
int_msg:
.asciz "Unknown interrupt\n\r"
.align 2
ignore_int:
pushl %eax
pushl %ecx
pushl %edx
push %ds
push %es
push %fs
movl $0x10,%eax
mov %ax,%ds
mov %ax,%es
mov %ax,%fs
pushl $int_msg
call _printk
popl %eax
pop %fs
pop %es
pop %ds
popl %edx
popl %ecx
popl %eax
iret
.align 2
setup_paging:
movl $1024*5,%ecx /* 5 pages - pg_dir+4 page tables */
xorl %eax,%eax
xorl %edi,%edi /* pg_dir is at 0x000 */
cld;rep;stosl
movl $pg0+7,_pg_dir /* set present bit/user r/w */
movl $pg1+7,_pg_dir+4 /* --------- " " --------- */
movl $pg2+7,_pg_dir+8 /* --------- " " --------- */
movl $pg3+7,_pg_dir+12 /* --------- " " --------- */
movl $pg3+4092,%edi
movl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */
std
1: stosl /* fill pages backwards - more efficient :-) */
subl $0x1000,%eax
jge 1b
xorl %eax,%eax /* pg_dir is at 0x0000 */
movl %eax,%cr3 /* cr3 - page directory start */
movl %cr0,%eax
orl $0x80000000,%eax
movl %eax,%cr0 /* set paging (PG) bit */
ret /* this also flushes prefetch-queue */
.align 2
.word 0
idt_descr:
.word 256*8-1 # idt contains 256 entries
.long _idt
.align 2
.word 0
gdt_descr:
.word 256*8-1 # so does gdt (not that that is any
.long _gdt # magic number, but it works for me :^)
Obviously, the code left performs paging and turn the execution to main. It also contains some crucial data such as the initializer of IDTR and GDTR.
11. Why execution is turned to main by 'ret'? Why not turn the execution by call? Draw a picture to describe it and give some evidences.
It is a logical problem. If we use call here, we admin that something call to the OS. But there is nothing but the OS during the head execution. ret might solve the logical dilemma.
The code evidence is as follow:
after_page_tables:
pushl $0 # These are the parameters to main :-)
pushl $0
pushl $0
pushl $L6 # return address for main, if it decides to.
pushl $_main
jmp setup_paging
L6:
jmp L6 # main should never return here, but
# just in case, we know what happens.
setup_paging:
movl $1024*5,%ecx /* 5 pages - pg_dir+4 page tables */
...
ret /* this also flushes prefetch-queue */
12. Describe the initialization of Interrupt Descriptor Table. Give an example.
In the main function, trap_init is called.
void trap_init(void)
{
int i;
set_trap_gate(0,÷_error);
set_trap_gate(1,&debug);
...
set_trap_gate(39,¶llel_interrupt);
}
set_trap_gate and _set_gate is as follow:
#define set_trap_gate(n,addr) \
_set_gate(&idt[n],15,0,addr)
#define _set_gate(gate_addr,type,dpl,addr) \
__asm__ ("movw %%dx,%%ax\n\t" \
"movw %0,%%dx\n\t" \
"movl %%eax,%1\n\t" \
"movl %%edx,%2" \
: \
: "i" ((short) (0x8000+(dpl<<13)+(type<<8))), \
"o" (*((char *) (gate_addr))), \
"o" (*(4+(char *) (gate_addr))), \
"d" ((char *) (addr)),"a" (0x00080000))
13. There are more than 20 instructions can be only executed in Privilege 0 in the IA-32 architectures. However, other instructions like 'cli' is not one of them. Why does the process with Priviledge 3 cannot execute it in linux 0.11?
The instructions cli and sti are under control of IOPL (Input/Output Privilege Level), which resdes in eflags. When the IOPL field is 0, the process with Privilege 3 cannnot execute them.
The code evidence is as follow:
/*
* INIT_TASK is used to set up the first task table, touch at
* your own risk!. Base=0, limit=0x9ffff (=640kB)
*/
#define INIT_TASK \
/* state etc */ { 0,15,15, \
/* signals */ 0,{ { },},0, \
/* ec,brk... */ 0,0,0,0,0,0, \
/* pid etc.. */ 0,-1,0,0,0, \
/* uid etc */ 0,0,0,0,0,0, \
/* alarm */ 0,0,0,0,0,0, \
/* math */ 0, \
/* fs info */ -1,0022,NULL,NULL,NULL,0, \
/* filp */ {NULL,}, \
{ \
{0,0}, \
/* ldt */ {0x9f,0xc0fa00}, \
{0x9f,0xc0f200}, \
}, \
/*tss*/ {0,PAGE_SIZE+(long)&init_task,0x10,0,0,0,0,(long)&pg_dir,\
0,0/* eflags */,0,0,0,0,0,0, \
0,0,0x17,0x17,0x17,0x17,0x17,0x17, \
_LDT(0),0x80000000, \
{} \
}, \
}
The task sturct of process 0 is initialized with INIT_TASK. Obviously, the eflags.IOPL is 0. The task structs of other processes are copy of INIT_TASK with no changing eflags.IOPL.
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
{
struct task_struct *p;
int i;
struct file *f;
p = (struct task_struct *) get_free_page();
if (!p)
return -EAGAIN;
task[nr] = p;
*p = *current; /* NOTE! this doesn't copy the supervisor stack */
...
p->tss.eflags = eflags;
...
}
14. It is the same as question 8.
15. Interrupt gate, trap gate and system call are set throuth setgate function. The difference between them is that the DPL of system call gate is 3, but the DPL of the other two is 0. Try to explain it.
When the DPL of a gate is 0, the gate can only be called by the processes with privilege 0, such as kernel.
When the DPL of a gate is 3, the gate can be called by the processes with privilege 3, such as user application.
Usually, the interrupt gate and trap gate are critical system function, which should be executed only by kernel.
However, the system call is designed for the user applications to use the functions provided by OS.
16. Why the Process 0 calls the 'movetouser_mode()' bofore forking the Process 1? How does the function work? Try to explain it.
In Linux, all the processes expect Process 0 should be created by an existing process running in the Privilege 3. The Process 0 is designed by OS designers and is running in Privilege 0 before
move_to_user_mode(). In order to conform the standards, Process 0 should callmove_to_user_modeto change the current privilege level before forking the Process 1.
The explanation above is given by The Art of Linux Kernel Design. But it seems unreasonable.
According to my best knowledge, if the privilege level does not change after call gate, the stack will not be switched.This might cause unexpected results. Stack switching during an interprivilege-level call should be the root cause.
The function move_to_user_mode imitate what the hardware do when an interrupt occurs.
Firstly, SS, ESP, EFLAGS, CS and EIP will be pushed into the current stack.
Then, the instruction iret will be executed. The hardware will do what it does while returning from a call gate, such as poping the registers to corresponding one.
The code is as follow:
#define move_to_user_mode() \
__asm__ ("movl %%esp,%%eax\n\t" \
"pushl $0x17\n\t" \
"pushl %%eax\n\t" \
"pushfl\n\t" \
"pushl $0x0f\n\t" \
"pushl $1f\n\t" \
"iret\n" \
"1:\tmovl $0x17,%%eax\n\t" \
"movw %%ax,%%ds\n\t" \
"movw %%ax,%%es\n\t" \
"movw %%ax,%%fs\n\t" \
"movw %%ax,%%gs" \
:::"ax")
The 0x17 in the code above indicates Privilege 3, LDT and Data Segment.
The 0x0f in the code above indicates Privilege 3, LDT and Code Segment.
17. Interrupt and exception are used widely in linux. What is the benefit?
Imporve the efficiency of CPU? (In fact, I do no really understand the question.)
18. The last five parameters of copy_process are 'long eip, long cs, long eflags, long esp, long ss', which reside in the stack when calling it. But there is no code about pushing the five arguments into the stack. Try to explain it.
The five arguments are pushed into stack by hardware when it executes the instruction int 80.
19. Analyse the function 'getfreepage' and give an introduction.
The code is as follow:
/*
* Get physical address of first (actually last :-) free page, and mark it
* used. If no free pages left, return 0.
*/
unsigned long get_free_page(void)
{
register unsigned long __res asm("ax");
__asm__("std ; repne ; scasb\n\t"
"jne 1f\n\t"
"movb $1,1(%%edi)\n\t"
"sall $12,%%ecx\n\t"
"addl %2,%%ecx\n\t"
"movl %%ecx,%%edx\n\t"
"movl $1024,%%ecx\n\t"
"leal 4092(%%edx),%%edi\n\t"
"rep ; stosl\n\t"
"movl %%edx,%%eax\n"
"1:"
:"=a" (__res)
:"0" (0),"i" (LOW_MEM),"c" (PAGING_PAGES),
"D" (mem_map+PAGING_PAGES-1)
:"di","cx","dx");
return __res;
}
In linux 0.11, mem_map is a table which keeps the usage of physical address.
Firstly, The code above scan mem_map backward and find the first free page, whoes value in the mem_map is 0.
Then, mark it used by changing its value to 1 and clear the free page.
Finally, return the address of the free page.
If no free pages left, return 0.
20. Analyse the function 'copypagetables' and give an introduction.
The code is as follow:
int copy_page_tables(unsigned long from,unsigned long to,long size)
{
unsigned long * from_page_table;
unsigned long * to_page_table;
unsigned long this_page;
unsigned long * from_dir, * to_dir;
unsigned long nr;
if ((from&0x3fffff) || (to&0x3fffff))
panic("copy_page_tables called with wrong alignment");
from_dir = (unsigned long *) ((from>>20) & 0xffc); /* _pg_dir = 0 */
to_dir = (unsigned long *) ((to>>20) & 0xffc);
size = ((unsigned) (size+0x3fffff)) >> 22;
for( ; size-->0 ; from_dir++,to_dir++) {
if (1 & *to_dir)
panic("copy_page_tables: already exist");
if (!(1 & *from_dir))
continue;
from_page_table = (unsigned long *) (0xfffff000 & *from_dir);
if (!(to_page_table = (unsigned long *) get_free_page()))
return -1; /* Out of memory, see freeing */
*to_dir = ((unsigned long) to_page_table) | 7;
nr = (from==0)?0xA0:1024;
for ( ; nr-- > 0 ; from_page_table++,to_page_table++) {
this_page = *from_page_table;
if (!(1 & this_page))
continue;
this_page &= ~2;
*to_page_table = this_page;
if (this_page > LOW_MEM) {
*from_page_table = this_page;
this_page -= LOW_MEM;
this_page >>= 12;
mem_map[this_page]++;
}
}
}
invalidate();
return 0;
}
The answer is no very difficult but very complicated. Maybe I will finish it someday.
21. When Process 0 creates Process 1, Process allocate a page for Process 1 for task_struct as well as Privilege 0 stack and the first page table respectively. Whose linear address space does the two pages reside, Kernel, Process 0, Process 1 or nothing?
The two pages reside in the linear address space of Kernel.
The code evidence is as follow:
Setup paging and allocate pages in linear address space of Kernel.
setup_paging:
movl $1024*5,%ecx /* 5 pages - pg_dir+4 page tables */
xorl %eax,%eax
xorl %edi,%edi /* pg_dir is at 0x000 */
cld;rep;stosl
movl $pg0+7,_pg_dir /* set present bit/user r/w */
movl $pg1+7,_pg_dir+4 /* --------- " " --------- */
movl $pg2+7,_pg_dir+8 /* --------- " " --------- */
movl $pg3+7,_pg_dir+12 /* --------- " " --------- */
movl $pg3+4092,%edi
movl $0xfff007,%eax /* 16Mb - 4096 + 7 (r/w user,p) */
std
1: stosl /* fill pages backwards - more efficient :-) */
subl $0x1000,%eax
jge 1b
xorl %eax,%eax /* pg_dir is at 0x0000 */
movl %eax,%cr3 /* cr3 - page directory start */
movl %cr0,%eax
orl $0x80000000,%eax
movl %eax,%cr0 /* set paging (PG) bit */
ret /* this also flushes prefetch-queue */
Allocate a page for task_struct and Privilege 0 stack
int copy_process(int nr,long ebp,long edi,long esi,long gs,long none,
long ebx,long ecx,long edx,
long fs,long es,long ds,
long eip,long cs,long eflags,long esp,long ss)
{
struct task_struct *p;
int i;
struct file *f;
p = (struct task_struct *) get_free_page();
...
}
Allocate pages for page tables
int copy_page_tables(unsigned long from,unsigned long to,long size)
{
...
for( ; size-->0 ; from_dir++,to_dir++) {
...
if (!(to_page_table = (unsigned long *) get_free_page()))
...
}
...
}
22. Similar to question 21.
23. Explain the code 'ljmp %0' in the function 'switch_to'.
The code is as follow:
#define switch_to(n) {\
struct {long a,b;} __tmp; \
__asm__("cmpl %%ecx,_current\n\t" \
"je 1f\n\t" \
"movw %%dx,%1\n\t" \
"xchgl %%ecx,_current\n\t" \
"ljmp %0\n\t" \
"cmpl %%ecx,_last_task_used_math\n\t" \
"jne 1f\n\t" \
"clts\n" \
"1:" \
::"m" (*&__tmp.a),"m" (*&__tmp.b), \
"d" (_TSS(n)),"c" ((long) task[n])); \
}
The instruction ljmp *mem48 can use the high 2 bytes as CS and the low 4 bytes as EIP pointed by mem48.
Well, __tmp.b is initialized with _TSS(n), which is owned by the Process n.
ljmp to a TSS means task switching.
24. Process 0 creates Process 1 through the function 'fork();', but it is executed twice. Try to explain it.
Process 0 creates Process 1 throuth the function fork(). During the time, Process 0 set the EIP of Process 1 with the address of the next instruction after int 0x80.
And the Process 0 and Process 1 share the same code.When transferring program control to the Porcess 1, it just executes the instruction pointed by CS:EIP.
Therefore, the funtion fork() seems to be executed twice. In fact, the Process 0 executes the whole of function fork() while the Process 1 executes the rest of function fork(), which is the part from int 0x80 to the end.
Reference
[1] The Art of Linux Kernel Design, Second Edition.
[2] IA-32 Architectures Software Developer vol-3a-part-1 Manual
[3] Wikipedia
[4] IA-32 Assembly Language Reference Manual
blog comments powered by Disqus